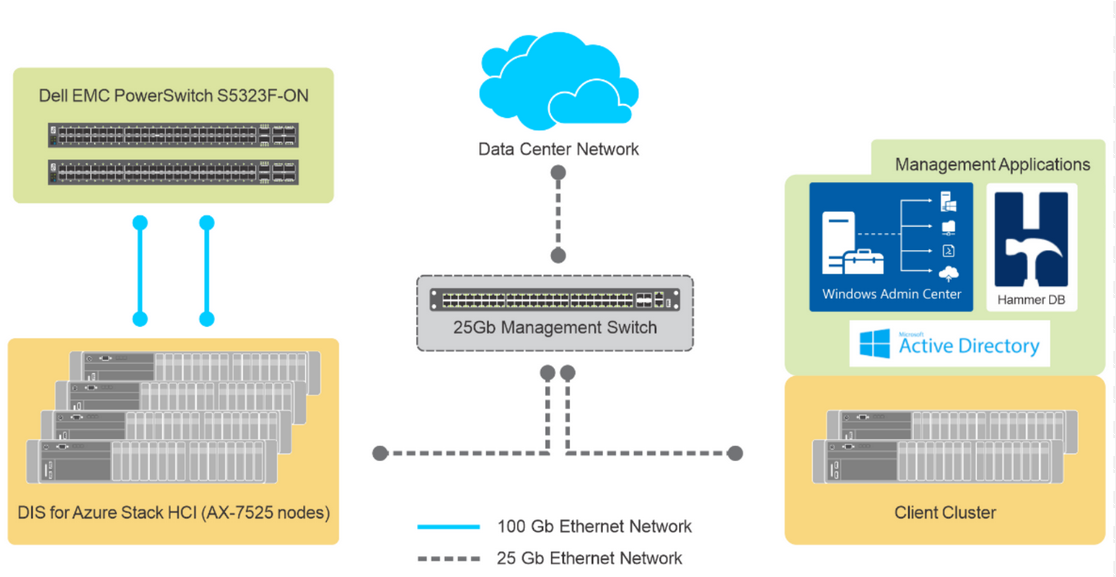
What Are NoSQL Databases?
Open source or not, NoSQL databases are non-relational, distributed databases that enable organizations to analyze huge volumes of data with the benefit of high availability, zero fault tolerance, and high scalability. These databases are compliant with the BASE principle, which is the opposite of the ACID property.
There are the following four types of NoSQL databases:
1. Key–Value DB: DynamoDB, Riak
2. Document DB: MongoDB, CouchDB. This is an extension of the key–value database. Document DB stores data as a document. Each document contains a unique key that is used for retrieval.
3. Column DB: Some examples are HBase and Big Table. Column DB stores tables as vertical sections of columns of data.
4. Graph DB: Neo4j. This document is based on graph theory and stores data as nodes, edges, and properties.
Key–Value Pair Stores
The word key–value is made up of key and value. Two pieces of data are associated with each other, and the key is a unique identifier that points them to each other. The value in a key–value pair is either the data being identified or a pointer to that data. The values can be of any scalar data type, like complex structures or integers, blob, list, JSON, etc., and can be stored as an array, string, JSON, etc. The performance of this type of store is excellent and can be used to store data for a plethora of use cases.
The concept of the key–value pair has existed since time immemorial. Any index directory is a good example, or telephone directory, dictionary, and so on. In the previous example, the key is the unique identifier of a person, business name, or phone number, and the respective values are the person’s name, business name, and phone number. Some common use cases for key–value databases are storing personal data, such as addresses, telephone numbers, etc.; product recommendations; caching and servicing; session management of multiplayer online games, and more. The question can be asked that since the same thing can be implemented in RDBMS as views, why would we use a key–value store. Key–value stores and other NoSQL methods have the advantages of speed, easy implementation, less need of programming skills, better pricing, and ease of integrating with features of web applications.
Figure 2-3 explains that a key–value store is basically a hash table. You link each data value with a unique key, and the key–value store uses this key to store the data by using a hashing function. The even distribution of hashed keys across data storage is a factor in the selection of hashing functions.
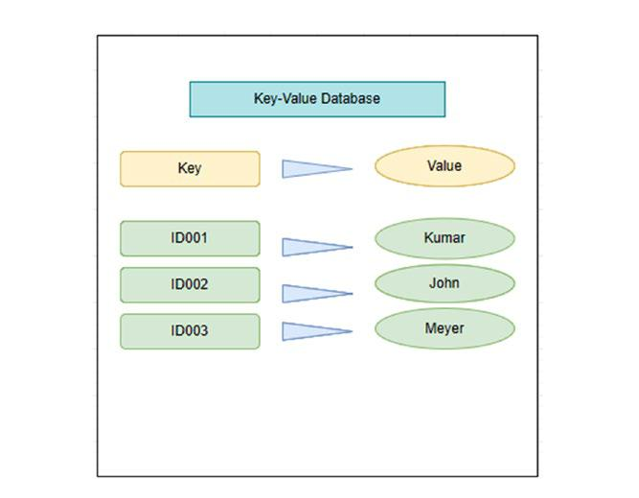
Figure 2-3. Key–value pair database
Key–value pairs consist of two elements: partition key and unique identifier.
The unique identifier is an identifier of a row that is unique for each row in the same partition. Items/values in the same partition are stored in row key order. If a new row is added to a table, it is ensured that the row is unique and that there is a unique identifier in terms of keys.
The partition key uniquely identifies the partition contained in the row. The stored values are not identified by the storage system software by itself. Hence, Table schema information must be provided and interpreted by the application. In other words, the key–value store retrieves the stored values by using the key as a reference point of lookup.
When an application retrieves a single row, the partition key enables Azure to go to the correct partition, and a unique identifier lets Azure identify the row in that partition being sought. In a range query, the application searches for a set of rows in a partition, specifying the start and end points of the set as row keys. This type of query is also very efficient and quick, if you have designed your keys according to the queries performed by the application.
Most key–value databases are intended for semi-structured databases and mostly support simple queries for retrieving data and insert/delete instances—only for writing instances. To modify a value (either partially or completely), an instance must overwrite the existing data for the entire value.
A key–value DB operation can be very fast for reading and writing. The DB is optimized for lookups and best used in use cases intended for the same. Key–value databases are very flexible, scalable, extendable, and distributable across multiple nodes on separate machines. This ability is a valuable, desirable, and strong feature of modern data warehouses. As time goes on, we are generating more and more data that is semi-structured in nature. Key–value DBs do not allow null values as keys or values. Irrespective it is not much, but as the number of nodes increases, storage capacity also increases.
In-memory caching is used in key–value databases to minimize read and write processing time; e.g., web applications can store user session details or customer product preferences by tracking users and storing data in key–value storage. As an example of another use case, real-time recommendations and advertising are often powered by key–value stores because the stores can quickly access and present new recommendations or ads as a web visitor moves throughout a site.
Some of the famous popular key–value DBs in the market are Riak, Redis, Project Voldemort, and Azure Storage Tables.


