Implement Lake House in AWS
Now, let us implement a lake house in AWS using the health data CSV file we used while building the lake house on Azure. We will go through the following steps to build the lake house in AWS:
• Create an S3 bucket to store the raw data.
• Create an AWS Glue job to convert the raw data into a delta table.
• Query the delta table using the AWS Glue job.
As a prerequisite, you should have permission for the IAM role, as in Figure 3-53.
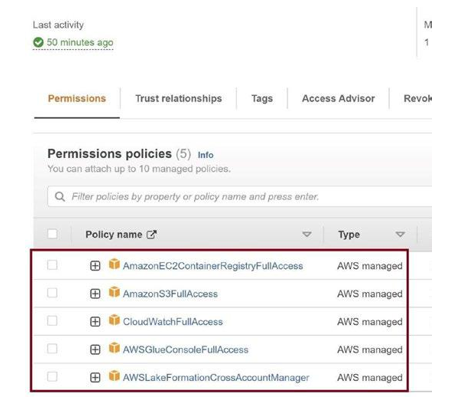
Figure 3-53. IAM permissions
Create an S3 Bucket to Keep the Raw Data
Let us create an S3 bucket, as in Figure 3-54, to keep the raw data and the delta table. The AWS Glue job will transform the raw CSV data to a delta table in parquet format and keep it in the S3 bucket.
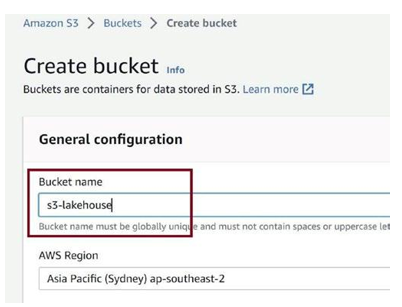
Figure 3-54. Create bucket
Click on the Create folder, as in Figure 3-55, to create a folder to keep the raw CSV file.
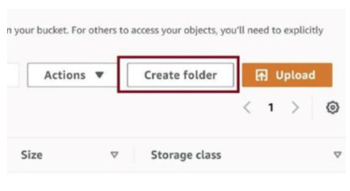
Figure 3-55. Create folder
Provide the name of the folder as raw data, as in Figure 3-56. Click on Create folder.
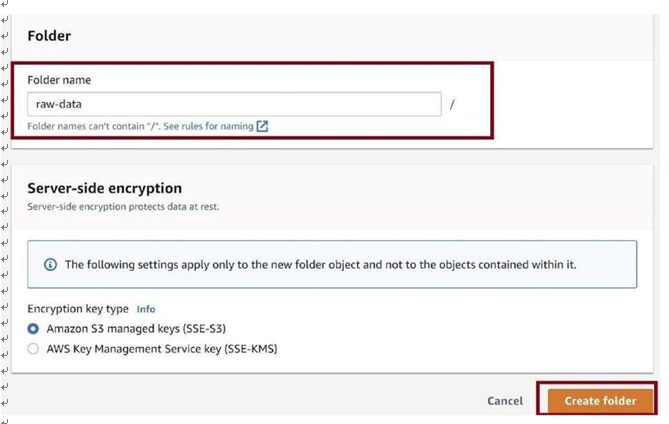
Figure 3-56. Create folder
Use the same steps to create another folder called delta-lake, as in Figure 3-57. We will keep the delta table here in this folder.
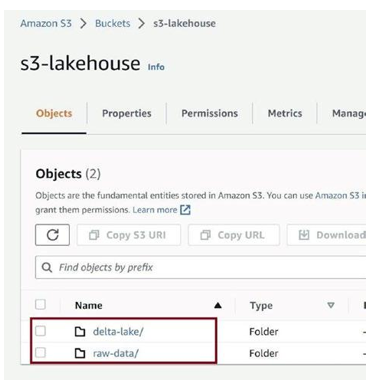
Figure 3-57. Folders in S3
Go to the raw-data folder and click on Upload, as in Figure 3-58. We need to upload the raw CSV file to this folder.
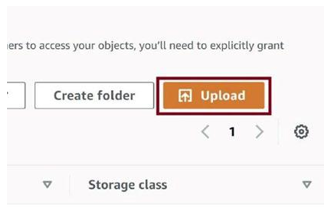
Figure 3-58. Upload raw CSV file.
Figure 3-59 depicts the uploaded CSV file in the S3 bucket. We will use the AWS Glue job to transform this CSV file into a delta table in parquet format.
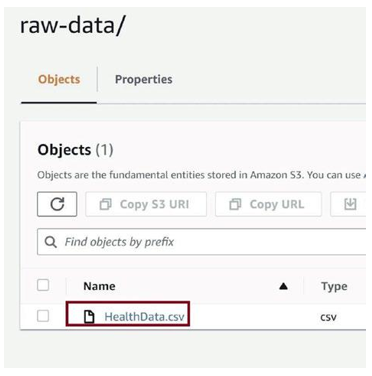
Figure 3-59. Uploaded raw CSV file


