
Graph Databases
Graph DBs use flexible representation to manage data. Data is stored using a graph structure. Graph DBs consist of two elements: (1) nodes (entities) and (2) edges (relations).
We typically look for global patterns and structures though graph DBs. Global pattern finding is done through visualization of interconnectedness of different points, represented through network graphs. It helps in dissemination of existing interconnected systems and different components or groups. It uses graph algorithms to model the existing system and create predictive algorithms.
Figure 2-5 explains one simple example of tracking the flow of money through multiple banks and countries. For example, a banned organization sends money to Person A, present in the United Kingdom, who sends it to another person, in the United States, who is a family member (e.g., brother) of a politically influential person.
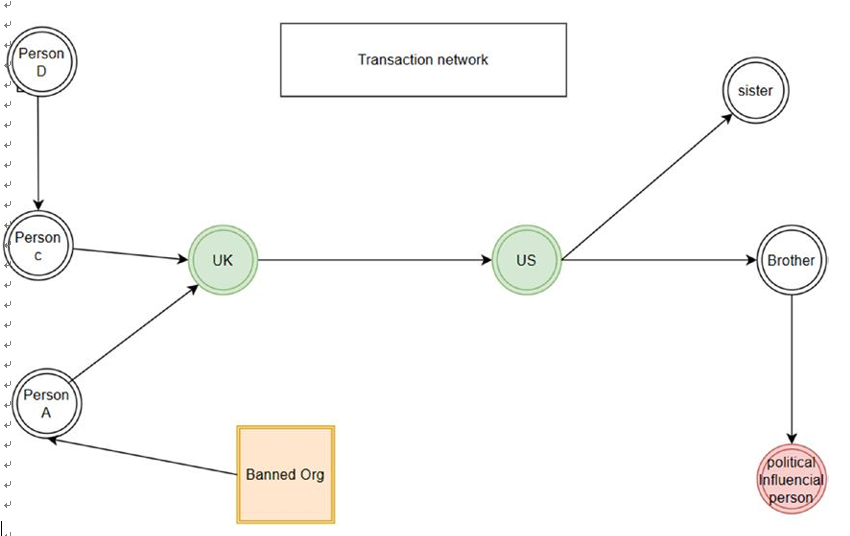
Figure 2-5. Anti-money laundering through a graph DB
For example, analysis of international and local payments for all network diagrams between sender of payments and receiver of payments is helpful for tracking money laundering and/or illegal activities. This analysis creates new opportunities for further data analysis and conclusions.
Graph databases are data processing–intensive databases. It requires both scale up and scale out abilities. For efficiency, their design focuses on powerful, multi-core, large memory machines; efficient data structures and multi-threading; and efficient algorithms. A valuable capability is their ability to handle different algorithms; e.g., weighted, unweighted, directed, undirected, cyclic, acyclic, sparse, dense, monopartite, bipartite, and k-partite, etc.
There are multiple types of processing done by graph databases. It could be based on nodes, relationships between nodes, processing these nodes within a subgraph independent of other subgraphs, while communicating to other subgraphs, etc. Graph databases focus on faster read and write using small queries. Graph DBs focus on high current scalability and operational robustness.
Choosing a platform for a graph DB involves many considerations, such as the type of analysis to be run, performance needs, the existing environment, and existing skills in the team. We gave examples of Apache Spark and Neo4j because they both offer unique advantages. However, we need to consider a hybrid approach. One part is for graph processing and another part for graphical representation; e.g., consider the spark of preprocessing and high-level filtering of massive datasets and Neo4j for presentation of graphs or specific or light processing of data.
When choosing Neo4j, we should consider several factors.
The platform is able to integrate with graph-based visualization tools and comes with prepackaged algorithms. It has the capability to handle complex algorithms and data that require deep path traversal. It performs better with complex, iterative algorithms that require iterative and performance sensitivity, and has intensive high memory locally. The platform is designed such that results are integrated with transactional workloads and enrich existing graphs.
A famous example of a graph structure would be to query the connections between users on a social network. Such interconnection between elements can be done with other databases also. An advantage of graph databases is their efficient and effective querying for highly interconnected data; e.g., famous automobile manufacturer Jaguar Land Rover uses graph analytics to give the business an interconnected view of supply chain and demand end to end, enabling it to form efficient answers to complex business questions. Graphs provide the means for understanding relations between sales, inventory, logistics, and supply chain, but, most important, it continues to learn.


