Data Lake, Lake House, and Delta Lake Concepts
Let us start with understanding the concept of the data warehouse. Using the extract, transform, load (ETL) process, structured relational data gets ingested into the data warehouse. It keeps tons of structured data that can be easily queried using Structured Query Language (SQL). Business intelligence tools connect to the data warehouse and extract meaningful insights from the stored data. The main goal of a data warehouse is to store data that can be consumed later to derive essential insights using business intelligence tools. The data warehouse is highly performant, and the business intelligence tools can run it with ease and speed. Data can be ingested by adhering to the database atomicity, consistency, isolation, and durability (ACID) properties. Figure 3-1 depicts a data warehouse.
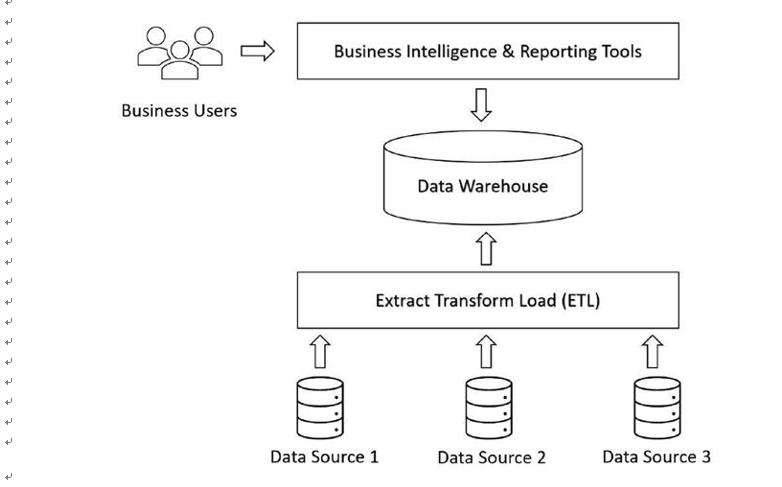
Figure 3-1. Data warehouse architecture
The data warehouse has been a perfect choice to serve as a data mart for structured data that can be consumed later to gather meaningful insights. However, as the data world evolved, unstructured non-relational data started to get generated at a very fast pace. Enterprises ended up generating tons of unstructured data that needed to be stored and managed along with the structured data. This led to the evolution of data lakes, which can store both structured and unstructured data. Enterprises ingested raw data like text files, videos, and images into the data lake. While consuming the data, enterprises processed it and used it for complex use cases like machine learning and artificial intelligence, along with gathering insights. The data warehouse helps you with getting business intelligence insights, and the data lake can be used for complex use cases involving machine learning, data analytics, and artificial intelligence. Figure 3-2 depicts a data lake. The data from various sources get ingested into the data lake. The data is further processed and used for machine learning, artificial intelligence, and business analytics purposes. The data can also be consumed by the data warehouse, where business users can run business intelligence tools to get business insights from the data.
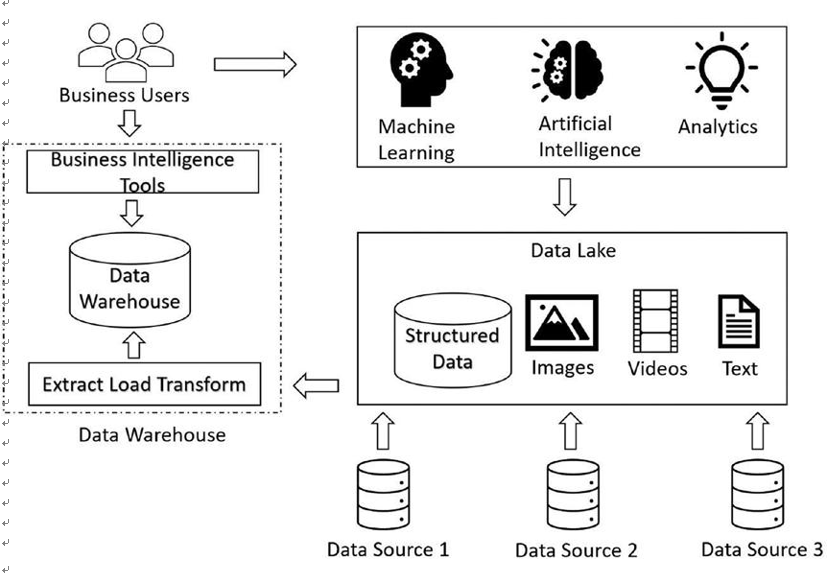
Figure 3-2. Data lake architecture
As the storage space needed for the data in the data lake increased, new complexities came up, like extracting data in a performant way, managing and governing the data, bringing in granular security to the data, and enforcing ACID (atomicity, consistency, isolation, and durability) based transactions. Enterprises were generating tons of data and consuming just a small portion of it. A lot of data stored in the data lake could not be consumed to generate any insights. Accessing the data from the data lake got slower as the amount being stored grew.