The data lake house is the solution to these problems. It is based on a modern data platform and stores a very large volume of structured and unstructured data, and also offers faster data retrieval. The data lake house is a fusion of a data lake and a data warehouse and brings in the best capabilities from each. The storage layer and the compute layer that processes the data stored in the storage layer are isolated and can scale independently. The following are the advantages of using a data lake house:
• Can store huge volumes of structured and unstructured data
• Can transact with data using ACID (atomicity, consistency, isolation, and durability) principles
• Low-cost storage with faster retrieval options
• Reliable, scalable, and durable data solution
• Metadata, indexing, versioning and caching features that make data querying highly performant and fast
• Can use Structured Query Language (SQL) to retrieve data
• Can build business intelligence–, machine learning–, and artificial intelligence–based solutions using a data lake house
• Can support open data storage formats like plain text, XML, JSON, parquet, and many more
• Can support streaming of real-time data
• Can enforce schema and governance and make the data stored usable
In the case of a data lake house, data from different sources gets ingested into the lake house in the raw format. On top of the lake house, there is an additional layer that keeps the curated data that can be accessed using Structured Query Language (SQL) or technologies like Spark SQL. Figure 3-3 depicts data lake house architecture.
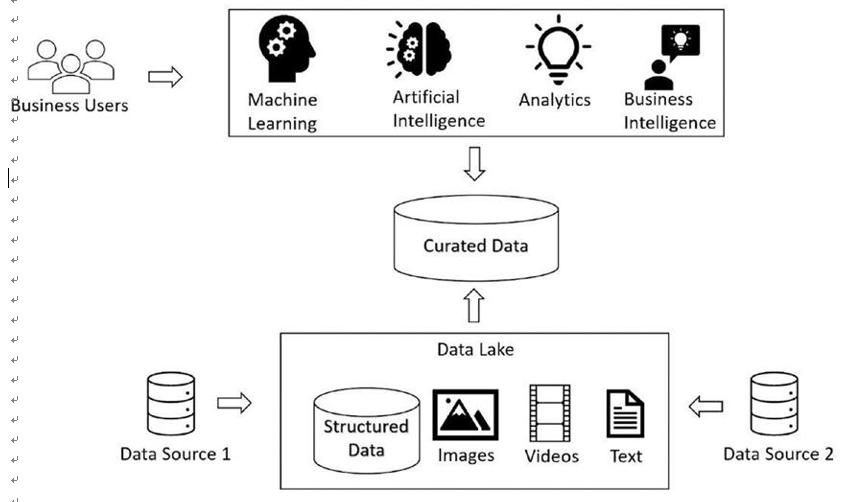
Figure 3-3. Lake house architecture
Figure 3-4 depicts the Databricks lake house architecture. Raw data is ingested into the underlying data lake. On top of that, there is a metadata and governance layer. Data is stored in an open file format, like parquet files, in the data lake. The metadata layer brings in capabilities like querying data using SQL, facilitating ACID transactions, indexing, data versioning, and many such features. There is also a Unity Catalog layer that brings in data governance, sharing, and auditing capabilities to the data stored in the lake house.
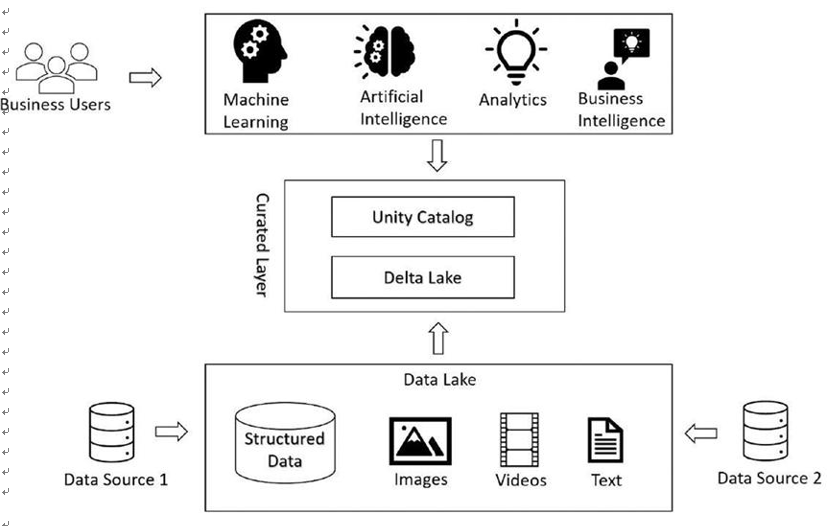
Figure 3-4. Databricks lake house architecture
Delta lake is an optimized storage layer that serves as the metadata layer for the lake house. It extends the underlying data stored in the data lake in raw format to support ACID transactions and querying capabilities using Apache Spark APIs or Spark SQL, or anything similar. It handles both streaming and batch data, all at one stop.
The delta lake comprises delta tables that do the trick. Delta tables are an optimized and secured storage layer on top of the data lake. It makes the transactions ACID compliant and lets you query databases just like relational databases. The data is stored in the Apache parquet format. The delta lake keeps track of audit trails of data changes and facilitates time travel of data. You can retrieve the previous version of the data in the row in a delta table. All the transaction logs are stored in the delta lake.
The Unity Catalog facilitates a one-stop data governance and compliance mechanism for the data stored in the delta log. You can define the security standards and governance once and use them everywhere across the delta lake. It supports tracing the data lineage and can help you trace data asset creation and usage across all languages and personas. It facilitates the auditing of the data stored in the delta lake. It supports data discovery by tagging and documenting the data.
You can follow the medallion architecture to store data in bronze, silver, and gold tables. Ingested raw data is stored in the bronze table. Filtered and cleaned data is stored in the silver table, and the processed data for business consumption is stored in the gold table. You can achieve this medallion architecture using the delta lake in the lake house data platform for Databricks. Figure 3-5 depicts the medallion architecture for the lake house.
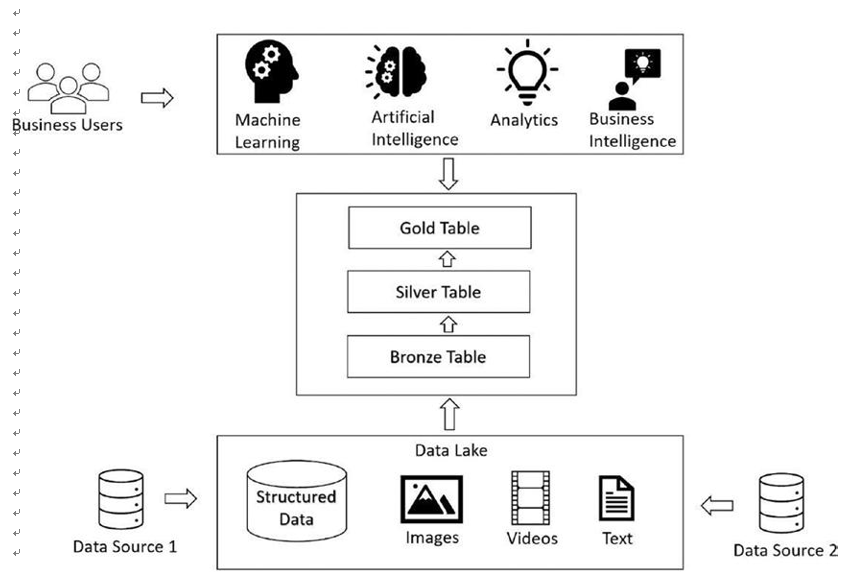
Figure 3-5. Databricks lake house medallion architecture