Create a Data Lake on Azure and Ingest the Health Data CSV File
Let us create an Azure data lake. On Azure, you can create a data lake on top of Azure Blob storage by enabling hierarchical namespaces. Azure Blob storage is highly robust and can store tons of structured data using hierarchical namespaces, and can serve as an Azure data lake. This is referred to as the Gen2 data lake on Azure. Let us go to the Azure portal and click on Create a resource as seen in Figure 3-6.

Figure 3-6. Create a resource
You will get navigated to the Marketplace, where you can search for Storage Account and then click on Create to spin up a storage account, as in Figure 3-7.
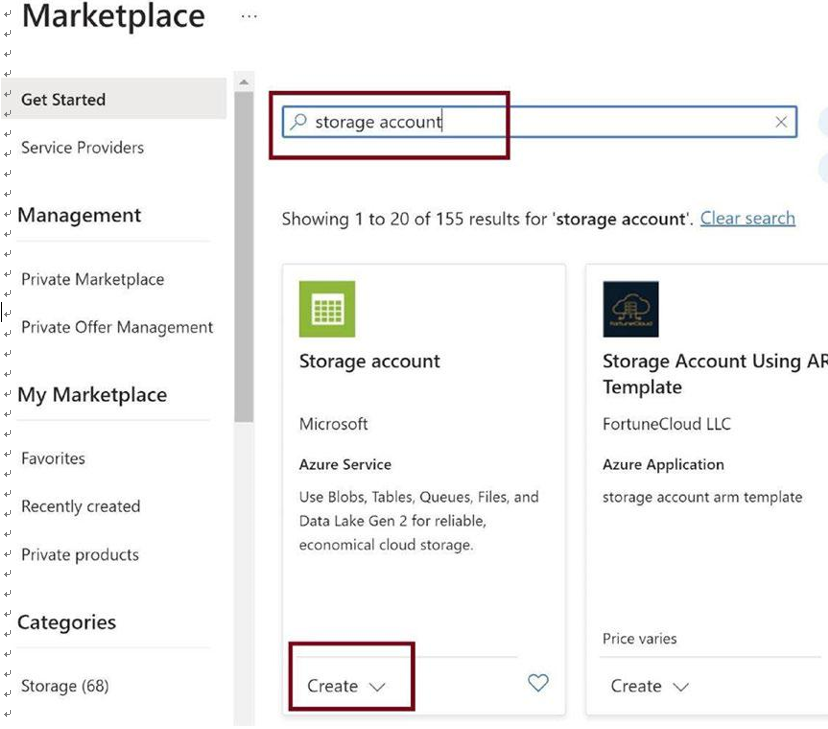
Figure 3-7. Search for Azure storage account
Provide the subscription, resource group, name, and region for the storage account, and then click on Next: Advanced, as in Figure 3-8.
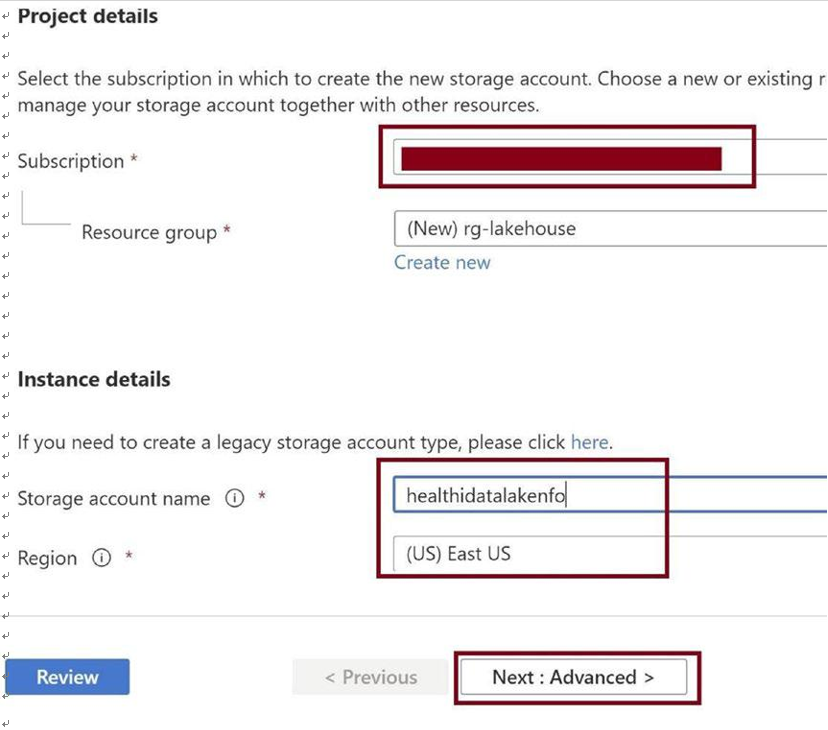
Figure 3-8. Provide basic details
Check Enable hierarchical namespace, as in Figure 3-9. This will facilitate creating a data lake on top of Azure Blob storage. Click on Review.
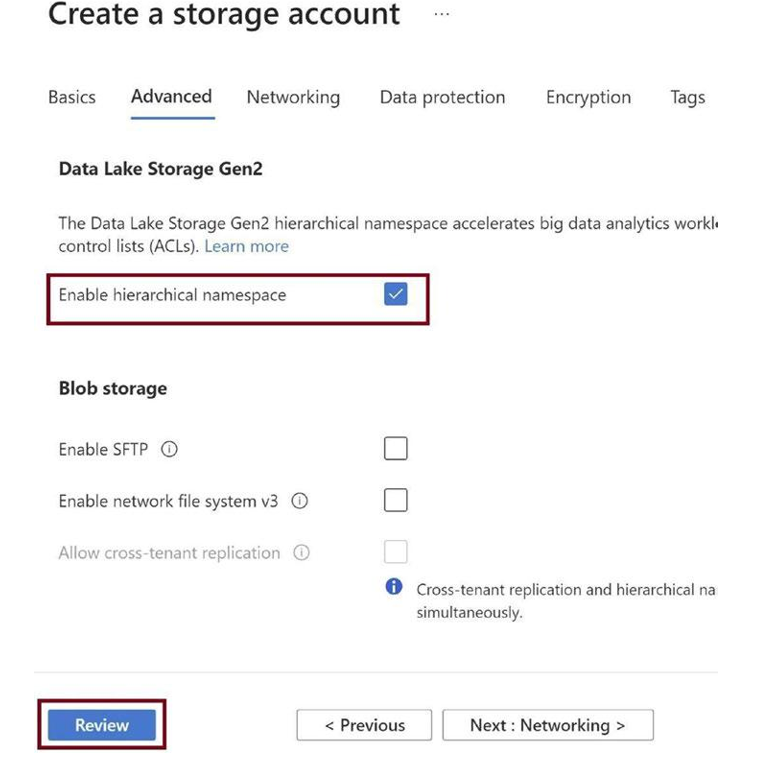
Figure 3-9. Enable hierarchical namespace
Click on Create, as in Figure 3-10. This will spin up an Azure data lake on top of Azure Blob storage.
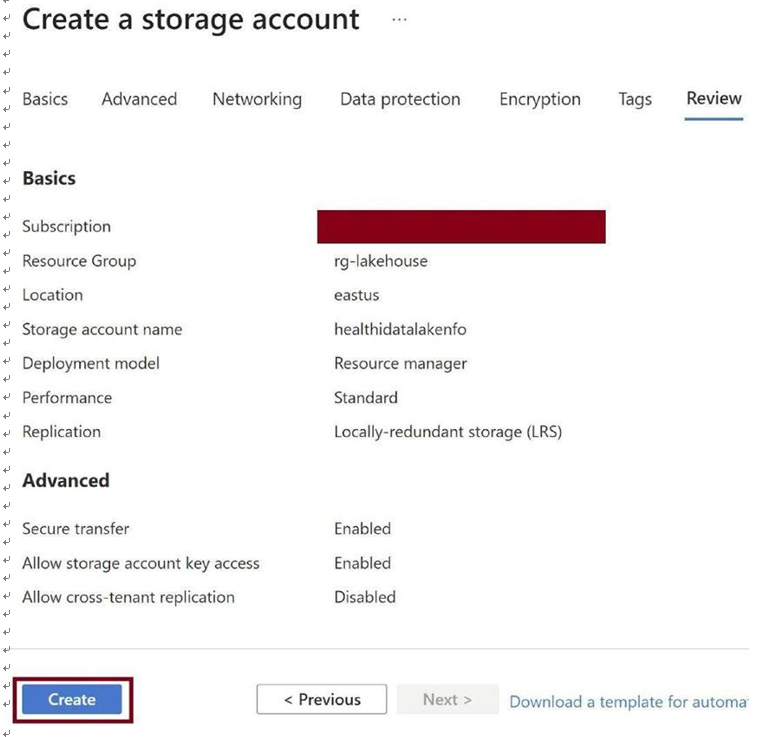
Figure 3-10. Click on Create button
Once the Azure storage account is created, navigate into it and click on Containers as in Figure 3-11. We need to add two containers named raw and processed. In the raw container, we will ingest the health data CSV file. We will process the CSV file in parquet format and keep it inside the processed folder.
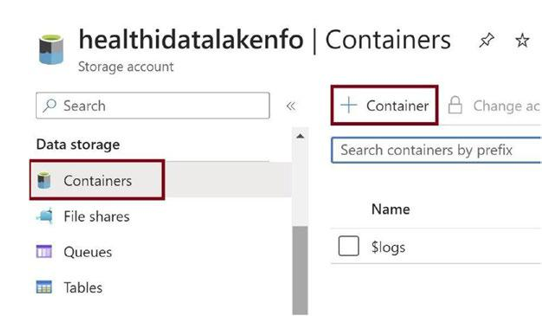
Figure 3-11. Click on Containers
Click on + Container as in Figure 3-12 to add these containers. Azure allows you to create a single container at a time, so you need to repeat this step to create the container twice.
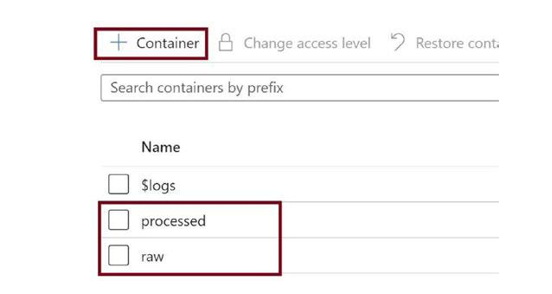
Figure 3-12. Add containers
Now we need to ingest the CSV file. Click on the raw container as in Figure 3-13.
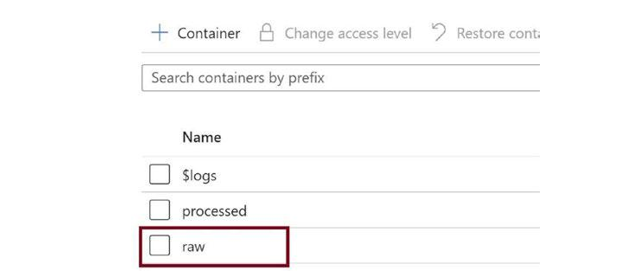
Figure 3-13. Click on the raw container
Click on Upload to upload the CSV file manually, as in Figure 3-14. In a real-world use case, data pipelines are used to ingest the data automatically. However, for simplicity, we are ingesting the data manually.
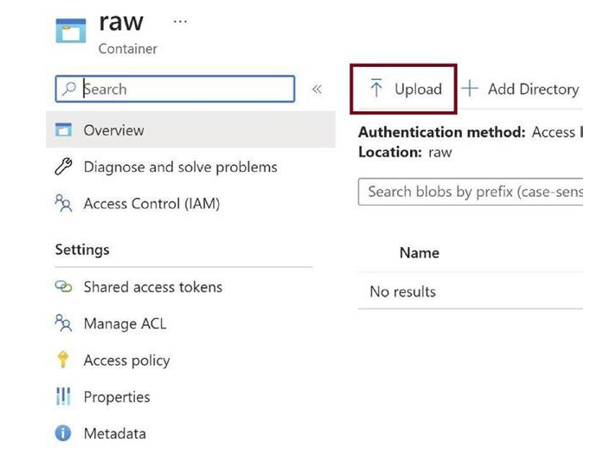
Figure 3-14. Click on Upload
Figure 3-15 depicts the uploaded CSV file. We will work on this file and move it to the lake house database after processing.
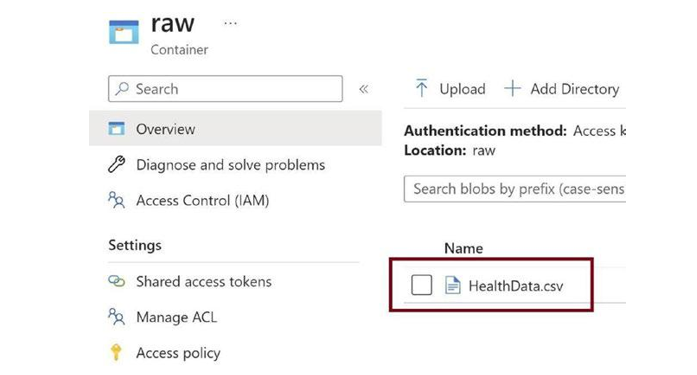
Figure 3-15. Ingested health data CSV file