Columnar DBs
Column DB is another type of NoSQL database where data are stored in a row and column table structure, like in a relational database, but are grouped in separate columns instead of rows. It means that, unlike traditional databases, the absence of predefined keys or column names provides schema-free flexibility when it comes to adding columns in real-time.
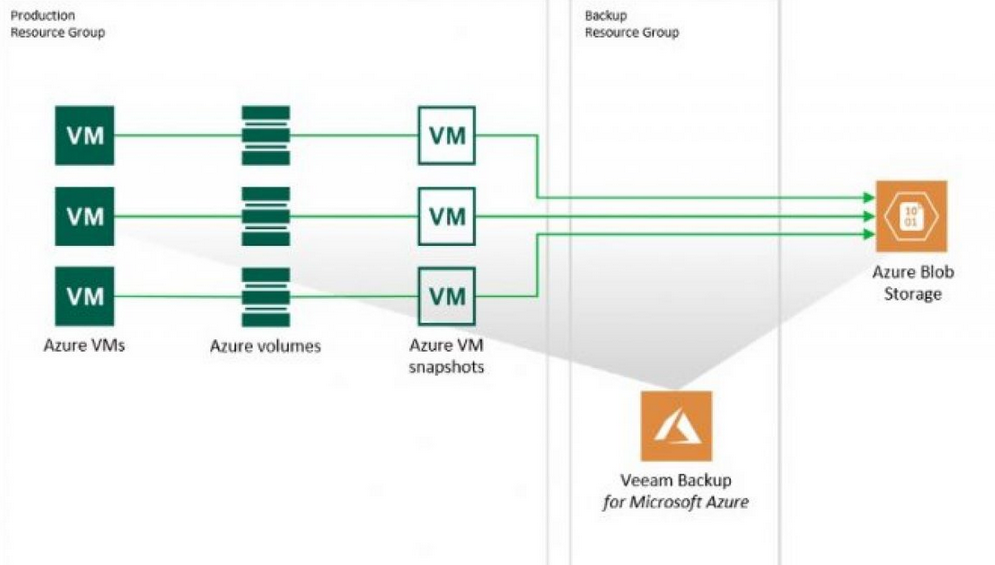
Figure 2-4 tries to demonstrate how all unique key values of three columns are stored and linked by unique keys.
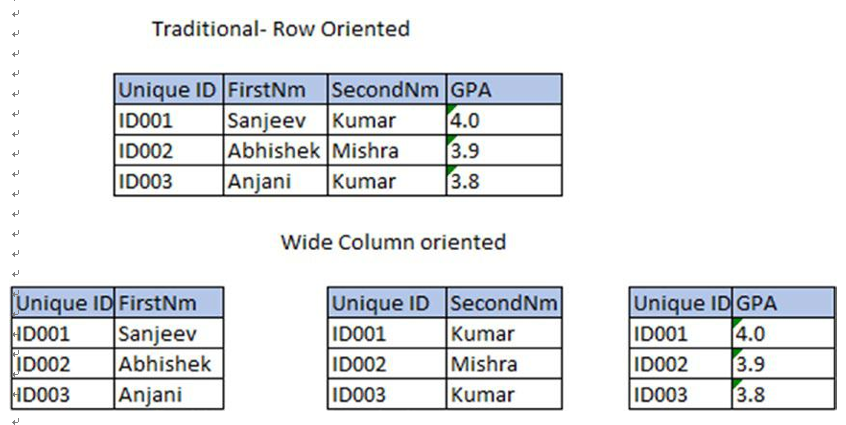
Figure 2-4. Document database
A column DB is one in which you can store a large amount of data within a column instead of a row. First, putting columnar data together allows compression algorithms to reduce the volume of disk storage required. Second, the main point of a column DB is its ability to store large amounts of data within a single column. Third, it improves read efficiency because there is no need for a row identifier, and this does allow for more rapid analysis of those column values.
However, when similar values are together in a columnar structure, it is not so good in terms of compression, and hence not so good performance-wise. Because one single insert could result in many rewrites as the data is shuffled to ensure similar values are adjacent to each other, if the data has frequent inserts and updates, this efficiency will eventually be lost.
So, the preceding criteria should be considered when deciding between column DB and traditional DB. While querying in CQL (Cassandra Query Language), column DBs allow for rapidly finding the location of fields and returning data. Data may need to be shuffled around to allow a new data row item to be inserted. In this case, traditional transactionally oriented databases will probably perform better in an RDBMS. Column DBs will best fit for business cases where speed of access to non-volatile data is important; for example, in (DSS) decision support system databases using a semantic layer to create visualization tools or create applications where speed of data access is the main differentiator. For example, you only need to review external data from commercial vendors to see business analytics.
Some examples of Column DBs are Apache Cassandra, HBase, and Cosmos DB. For Cassandra; instead of declaring a primary server; data is distributed in a cluster of nodes, each of which can process client requests. This provides an “always available” architecture that is extremely appealing for enterprise applications where having no downtime is critical. To write very large amounts of data efficiently, the trade-off option between read and write speed options are provided based on BASE principal. Even though there are several levels of trade-off between data consistency and availability for developers, when performing a write operation, replicas of a new record are stored across multiple cluster nodes and are created in parallel. Only a subset of those nodes needs to complete a replica update for the write operation to be considered successful, which means that the write operation can finish in less time.


